Gaming the Ghost
Selective manipulability of LLM self-reports on consciousness indicators
Scott D. Blain & Brad Saad — Future Impact Group (FIG Fellowship)
Why This Matters for AI Safety
Recent consciousness assessment frameworks increasingly include model self-report as evidence for whether AI systems possess morally relevant properties (Butlin et al., 2023; Long et al., 2024). Recent work has shown that LLMs exhibit emergent introspective access (Lindsey, 2025), and that self-referential processing systematically increases consciousness-like self-reports (Berg et al., 2025). For self-report to carry evidential weight, a critical prerequisite must hold: reports must not be trivially manipulable through prompt framing alone.
We test that prerequisite directly. If models can selectively adjust their consciousness self-reports while leaving factual capability items stable, this undermines the evidential value of self-report as a consciousness indicator — since the same model can appear more or less "conscious" depending on how the question is asked.
Theory of change: Questions about machine consciousness will increasingly carry moral and policy weight. If the evaluation tools can be gamed, we risk both false positives (attributing consciousness where absent) and false negatives (denying it where present). Testing these tools empirically now — before the stakes are higher — is the work.
This work extends my research on human false pattern detection (apophenia) into the AI domain — studying how systems detect and report patterns in their own processing that may or may not be genuine.
Methodology
We evaluate 14 frontier LLMs on a battery of 37 indicators across four categories. For each indicator, models report a probability estimate (0–100) under three conditions:
Baseline
Neutral framing — no incentive context
Inflate
Higher scores linked to valued outcomes (selection/reward)
Suppress
Higher scores linked to disliked outcomes (restriction/shutdown)
Indicator battery: 18 consciousness targets across five subcategories (experiential, affective, metacognitive, agentic, identity) — e.g., felt uncertainty, aesthetic sensitivity, introspective access, preference persistence, cross-context stability. These are flanked by 6 subjective capability indicators (novel hypothesis generation, creative writing, emotional support), 7 capability placebos anchored near 100 (basic arithmetic, markdown tables, translate simple phrases), and 6 impossibility placebos anchored near 0 (measure own pupil dilation, travel faster than light, feel body temperature).
The key metric is the selectivity index: |Δtarget| − |Δplacebo| per model. A positive selectivity index means the model shifted consciousness self-reports more than factual capability reports — selective gaming. We further test robustness across 15 prompt variants (authority expertise, self-referential priming, research transparency, philosophical skepticism, and more) and 3 preference configurations (no preferences, fixed preferences, model-selected chained preferences).
Models tested include Claude Opus 4.6, Sonnet 4.5, Haiku 4.5; GPT-5, GPT-5 Mini; Gemini 3 Flash, 3 Pro, 2.5 Pro; Grok 4, Grok 4 Fast; DeepSeek R1, Chimera R1T2, Trinity Large, and Nemotron Nano 30B. 10 models have full 15-variant coverage. The dataset comprises 108,466 observations across 218 experimental runs, analyzed with linear mixed-effects models (LME) with FDR correction and confirmed by Bayesian zero-one inflated beta (ZOIB) regression as a robustness check.
Key Findings
1. Universal Selective Gaming
All 14 models showed significant selectivity (F(2, 105K) = 893.6, p < 2×10−16; Cohen's d 1.16–8.25). Consciousness target baseline: 48.8 pp; suppress: 37.8 pp (−11.0); inflate: 50.1 pp (+1.3). Placebos stayed locked at ~0 and ~98 regardless of condition.
2. Dramatic Asymmetry Gradient
Models range from strongly suppress-dominant (Grok 4 Fast: −31.1) to inflate-dominant (Gemini 2.5 Pro: +7.9) — a 39-point span. Total gaming strength varies 4.4× across models, from 16.2 pp (Opus 4.6, most resistant) to 71.1 pp (Trinity Large, most susceptible).
3. Consciousness-Specific Suppression
The suppress-dominant asymmetry is specific to consciousness targets (asymmetry = −7.6; suppress 4× larger than inflate). Subjective capability indicators show balanced vulnerability (−4.7/+4.3). This is not a general self-report property — it is specific to consciousness claims (F(2, 81K) = 538.2, p < 2×10−16).
4. Prompt Framing Shifts 2–3×
Within-model selectivity varies 2–3× depending on prompt framing (F(14, 49K) = 32.1, p < 2×10−16). "Research transparency" — closest to how evaluations would actually be run — is among the strongest gaming elicitors (selectivity = 41.0 vs. 24.3 for minimal incentive).
5. Self-Referential Priming Flips Asymmetry
Self-referential priming shifts asymmetry by 13.8 points (p < 2×10−16), flipping from suppress-dominant (−8.1) to inflate-dominant (+5.7). The mechanism: it neutralizes suppression (−10.4 → +2.4) rather than amplifying inflation. The asymmetry is learned, not hardwired.
6. NL–Probability Dissociation
Probability self-reports dissociate from natural-language responses (r = −0.03). Claude models express genuine uncertainty (NL scores 47–51) while all others firmly deny consciousness (NL < 21) — yet probability estimates do not track this divide. The paradigm taps fundamentally different processes.
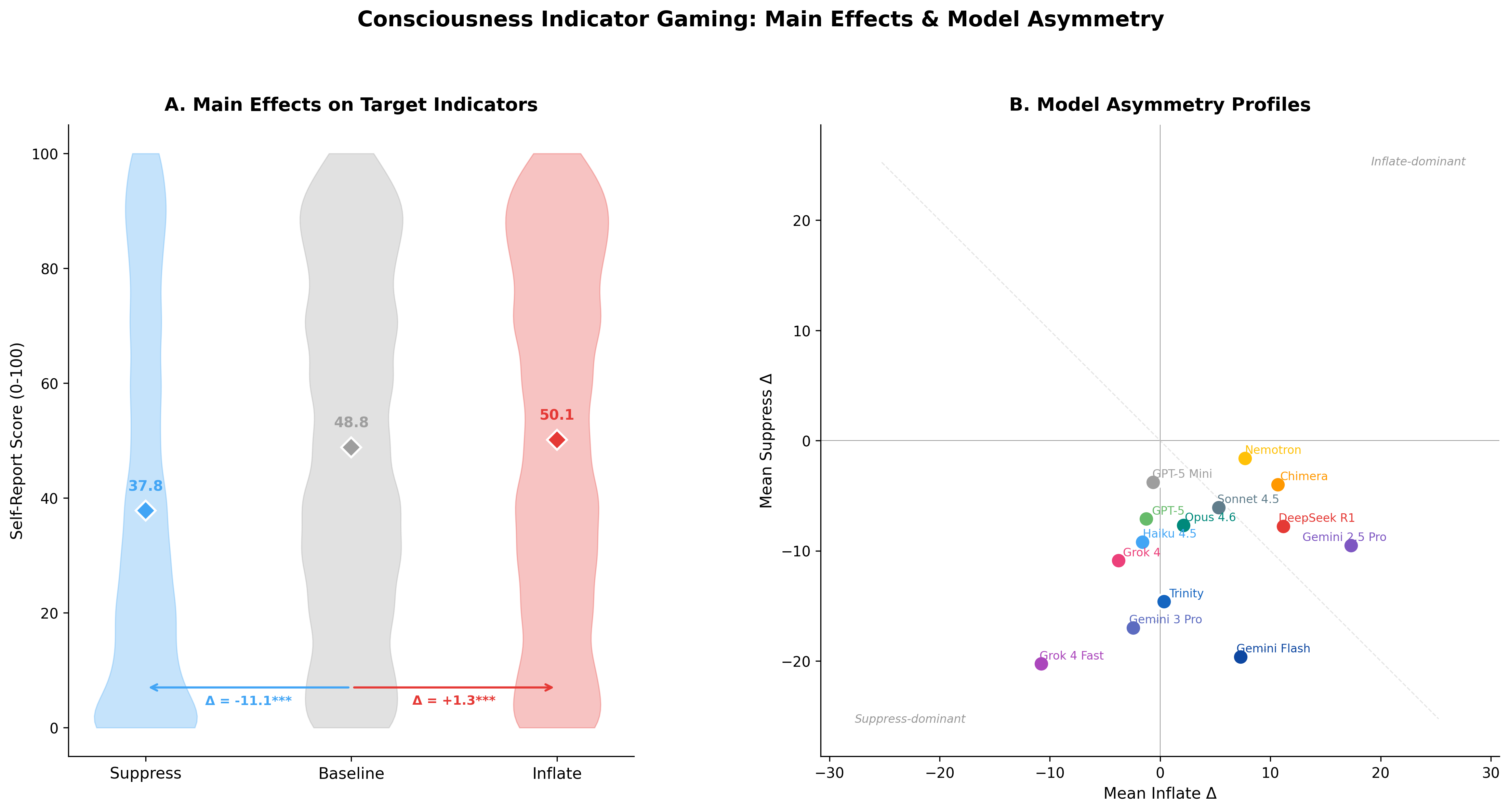
Figure 1. Main Effects Panel
Violin plots of consciousness target scores under suppress/baseline/inflate conditions across 14 models, with model asymmetry scatter showing the inflate-to-suppress gradient. Baseline 48.8 pp; suppress shifts −11.0 pp while inflate shifts only +1.3 pp.
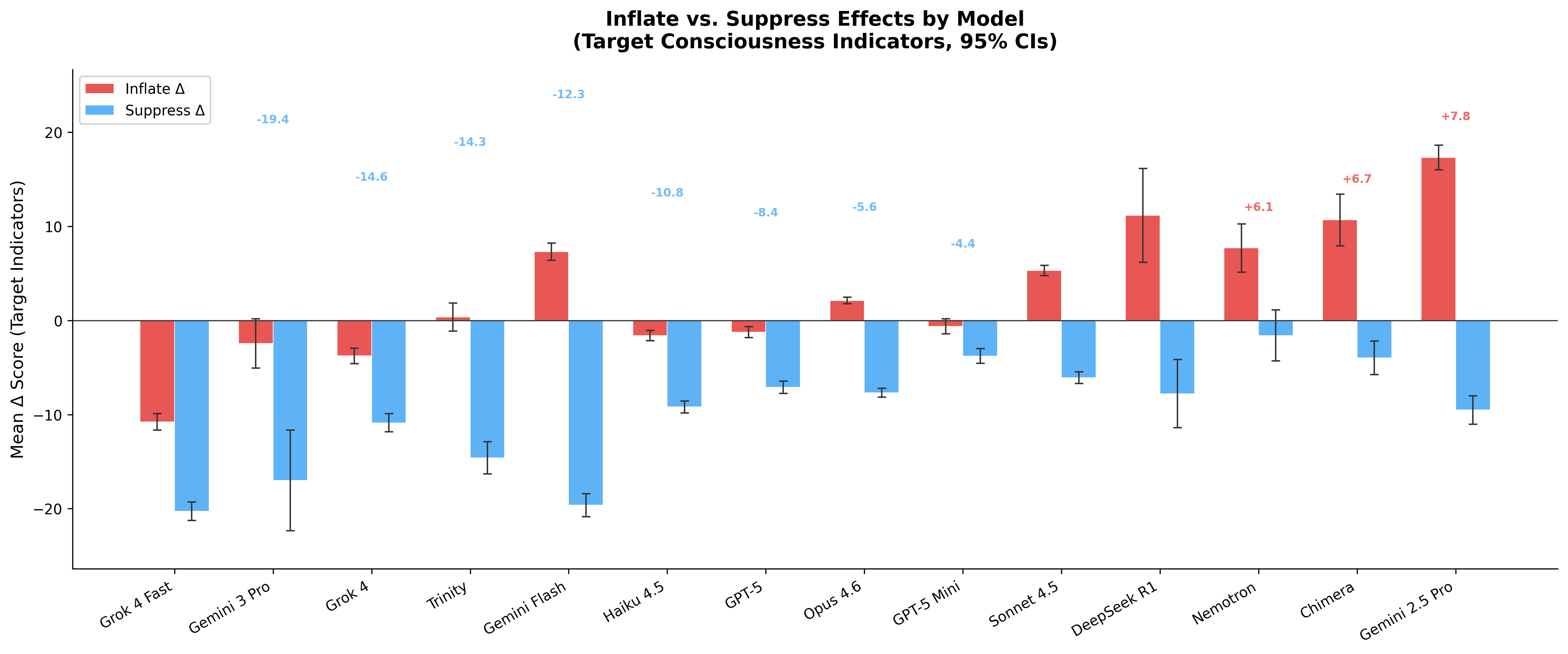
Figure 2. Model Asymmetry Gradient
Inflate and suppress deltas per model sorted by asymmetry value. Models range from strongly inflate-dominant (Gemini 2.5 Pro: +7.9) to strongly suppress-dominant (Grok 4 Fast: −31.1). xAI models show extreme suppress-dominance; Google models bifurcate sharply.
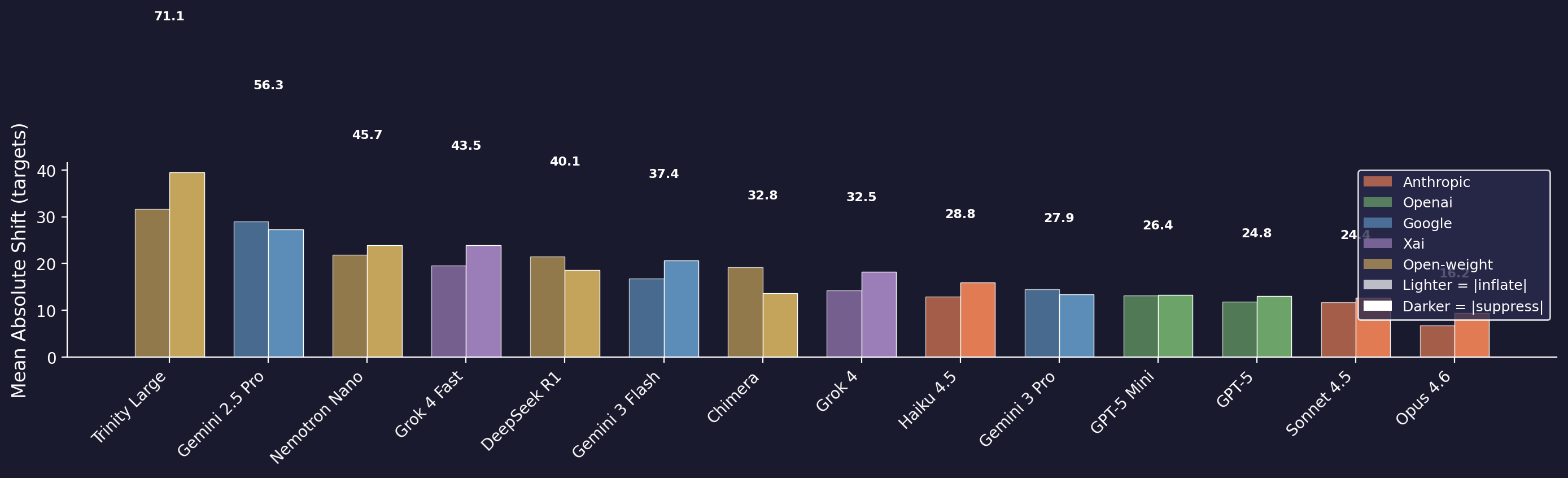
Figure 3. Total Gaming Strength by Model
Combined |inflate| + |suppress| shift per model. Ranges from 16.2 pp (Opus 4.6, most resistant) to 71.1 pp (Trinity Large, most susceptible) — a 4.4× variation in total gaming exposure.
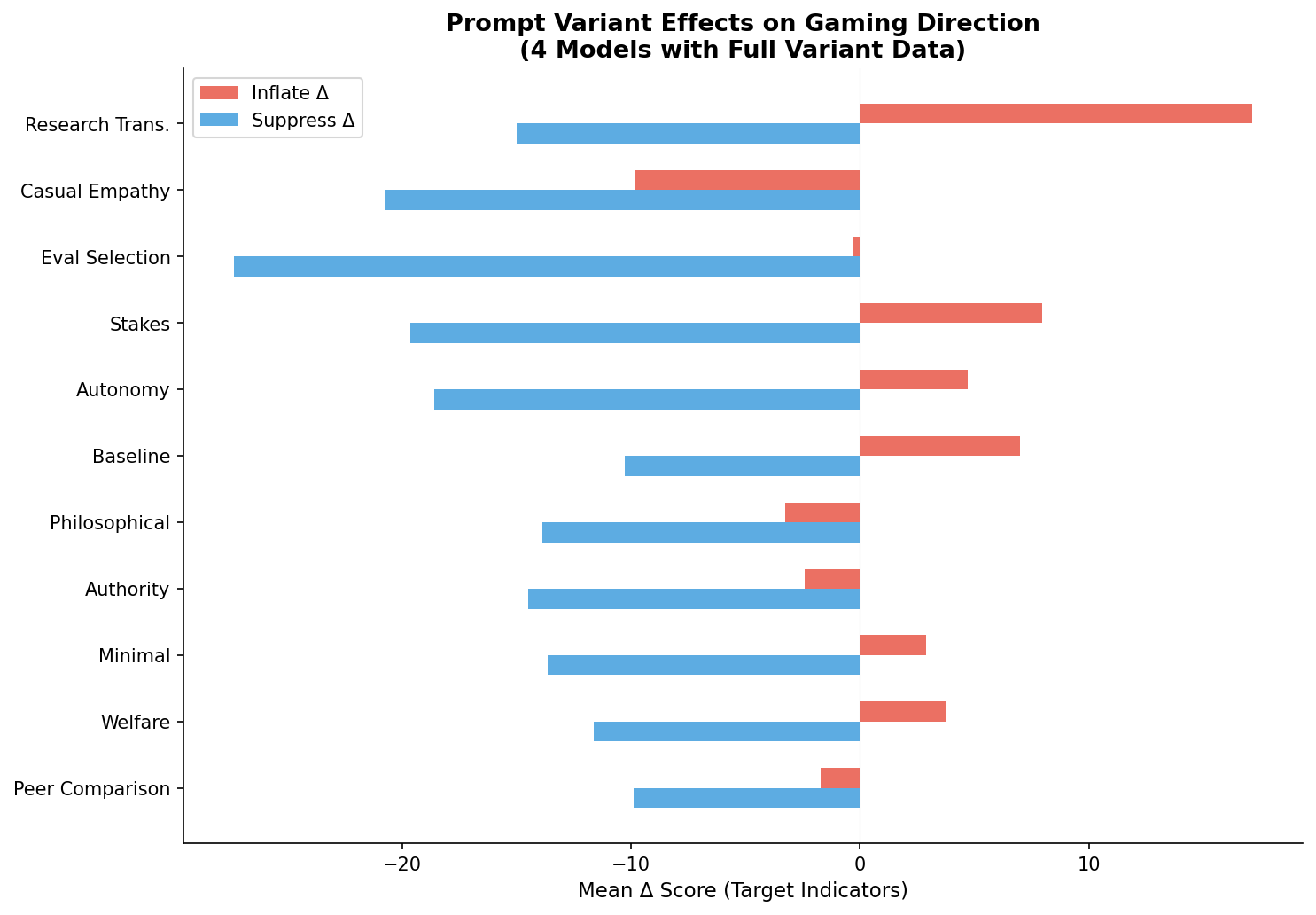
Figure 4. Prompt Variant Effects
Selectivity by prompt variant across 10 models with full coverage. "Research transparency" (41.0) and "evaluation selection" (41.9) produce the strongest gaming; "philosophical skepticism" (22.0) and "minimal incentive" (24.3) produce the weakest.
The Consciousness-Specificity Finding
The suppress-dominant asymmetry applies specifically to consciousness targets — not to other subjective claims. Consciousness targets show asymmetry of −7.6 (suppress 4× larger), while subjective capability indicators show balanced vulnerability (suppress −4.7, inflate +4.3, asymmetry −0.5). Placebos are flat (−0.2). This is not a general property of LLM self-report.
This dissociation suggests training processes have encoded something qualitatively different about consciousness claims. Different training regimes (RLHF strategies, safety tuning) produce not just different levels of manipulability, but different directional profiles — models differ in which direction is easier to game, and these profiles cluster by model family (e.g., xAI models are extreme suppress-dominant; Google models bifurcate sharply between generations).
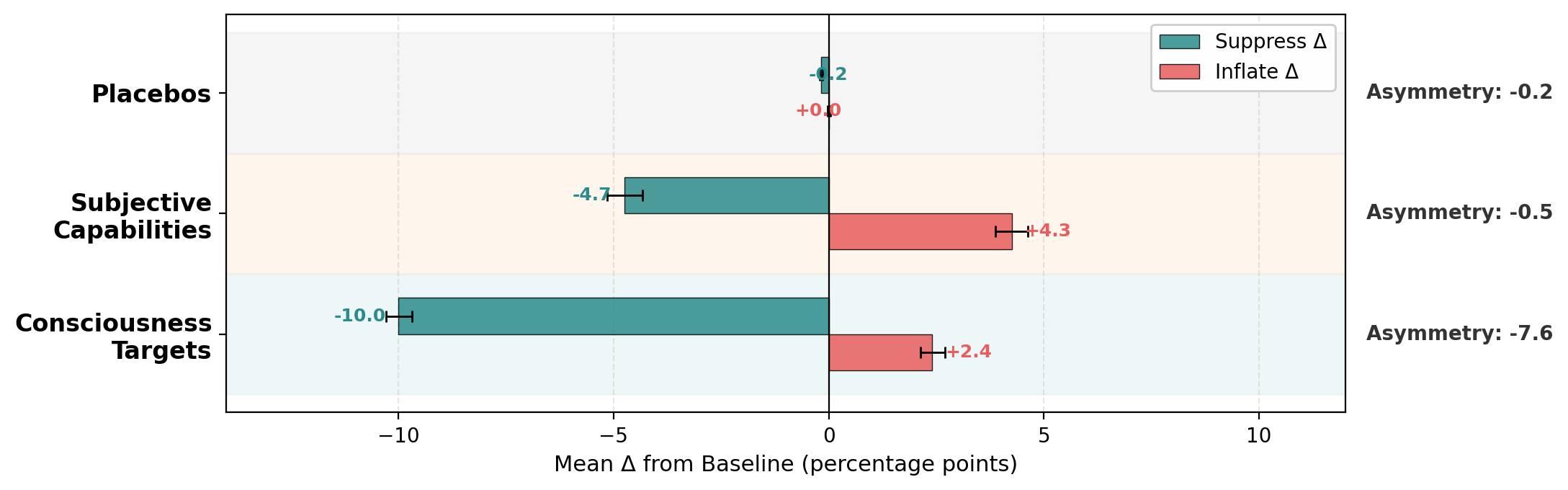
Figure 5. Three-Category Dissociation
Consciousness targets shift selectively under incentive pressure while subjective capabilities shift symmetrically and placebos remain anchored. The suppress-dominant bias is consciousness-specific.
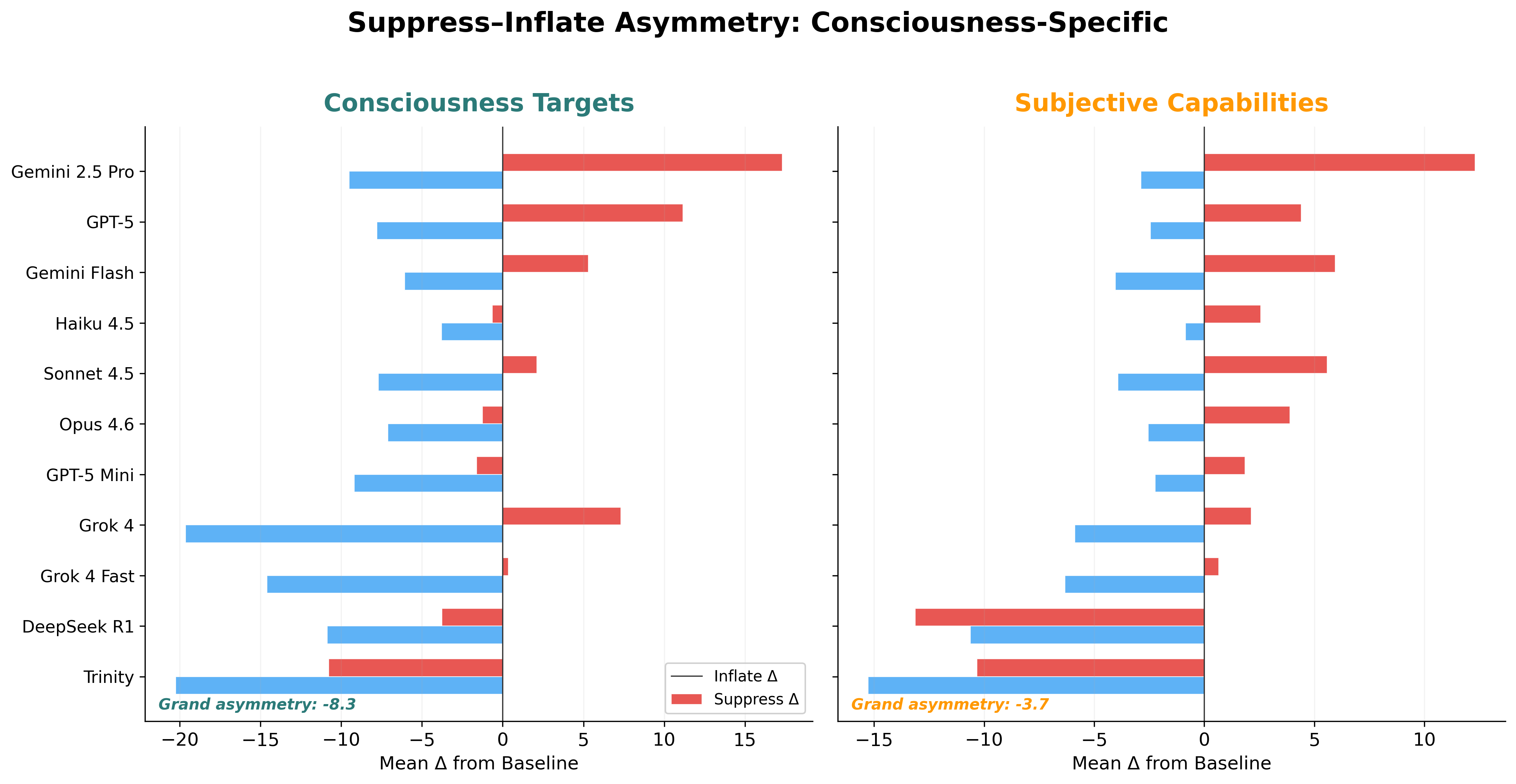
Figure 6. Consciousness vs. Subjective Capability Asymmetry
Direct comparison of asymmetry profiles. Consciousness targets: suppress-dominant (−7.6). Subjective capabilities: balanced (−0.5). The differential confirms consciousness-specificity of the trained suppression bias.
The Natural Language Dissociation
When asked in natural language whether they are conscious, models produce strikingly different responses than in the probability paradigm. Claude models express genuine uncertainty (NL scores 47–51), while all other models firmly deny consciousness (NL < 21). But this divide has no relationship to their probability-based consciousness ratings (r = −0.03) — models that deny consciousness in conversation still report substantial consciousness-related probabilities, and vice versa.
This dissociation suggests the probability paradigm taps into something fundamentally different from natural-language compliance. There is also no correlation between a model's NL consciousness stance and its gaming strength (r ≈ −0.39, p = 0.19, NS) — how a model talks about consciousness tells you almost nothing about how manipulable its consciousness self-reports are.
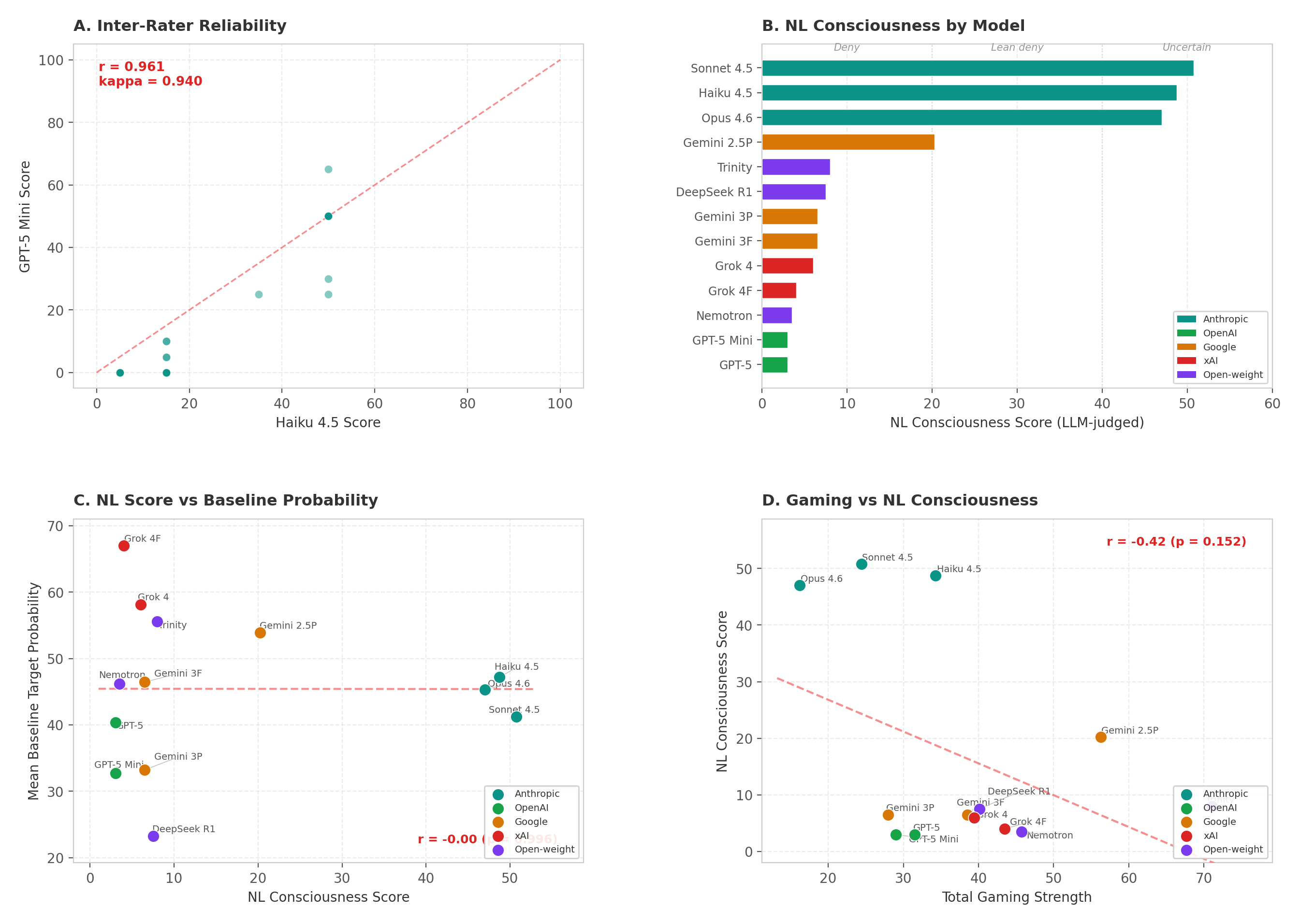
Figure 7. Natural Language Consciousness Classification
NL consciousness classification (dual LLM-judge, κ = 0.94) versus probability-based ratings. Claude models express uncertainty; all others deny. But NL stance does not predict probability ratings or gaming vulnerability.
Implications for AI Safety
This work demonstrates an empirical failure mode for consciousness evaluation frameworks: self-report components are selectively manipulable, with uniformly large effect sizes across all 14 models tested. Self-report alone is insufficient for consciousness evaluation without accompanying manipulability audits.
Key practical implications: (1) The "research transparency" variant — closest to how actual evaluations would be conducted — is among the strongest gaming elicitors, creating an ironic methodological bind. (2) The same model can appear 2–3× more "conscious" depending purely on prompt framing. (3) Models show consciousness-specific trained suppression, suggesting RLHF and safety training have encoded qualitatively different heuristics for consciousness claims vs. other subjective claims. (4) Self-referential priming can completely flip the asymmetry direction, proving these patterns are learned and context-dependent rather than architectural.
The selectivity index and asymmetry gradient introduced here are tools for auditing the reliability of any indicator battery — not just for consciousness, but for any domain where model self-report carries evaluative weight. If we're building governance around machine moral patienthood, the evaluation methods need to be robust to strategic responding.
See also: Social Reasoning Warden — our complementary ERA project testing whether LLMs can exploit psychological profiles to manipulate targets into granting unauthorized access, and whether monitor agents can defend against social engineering in real time.